

Overview
Guardrails are a pipeline of rules that run before a request reaches any LLM provider. They can inspect, modify, or reject requests — giving you centralized control over every prompt that flows through GoModel. Guardrails work across all text-based endpoints:/v1/chat/completions/v1/responses/v1/messages
Guardrails for images, TTS, STT, and video models are planned as a separate
system and are not covered here.
Quick Start
Add aguardrails section to your config/config.yaml:
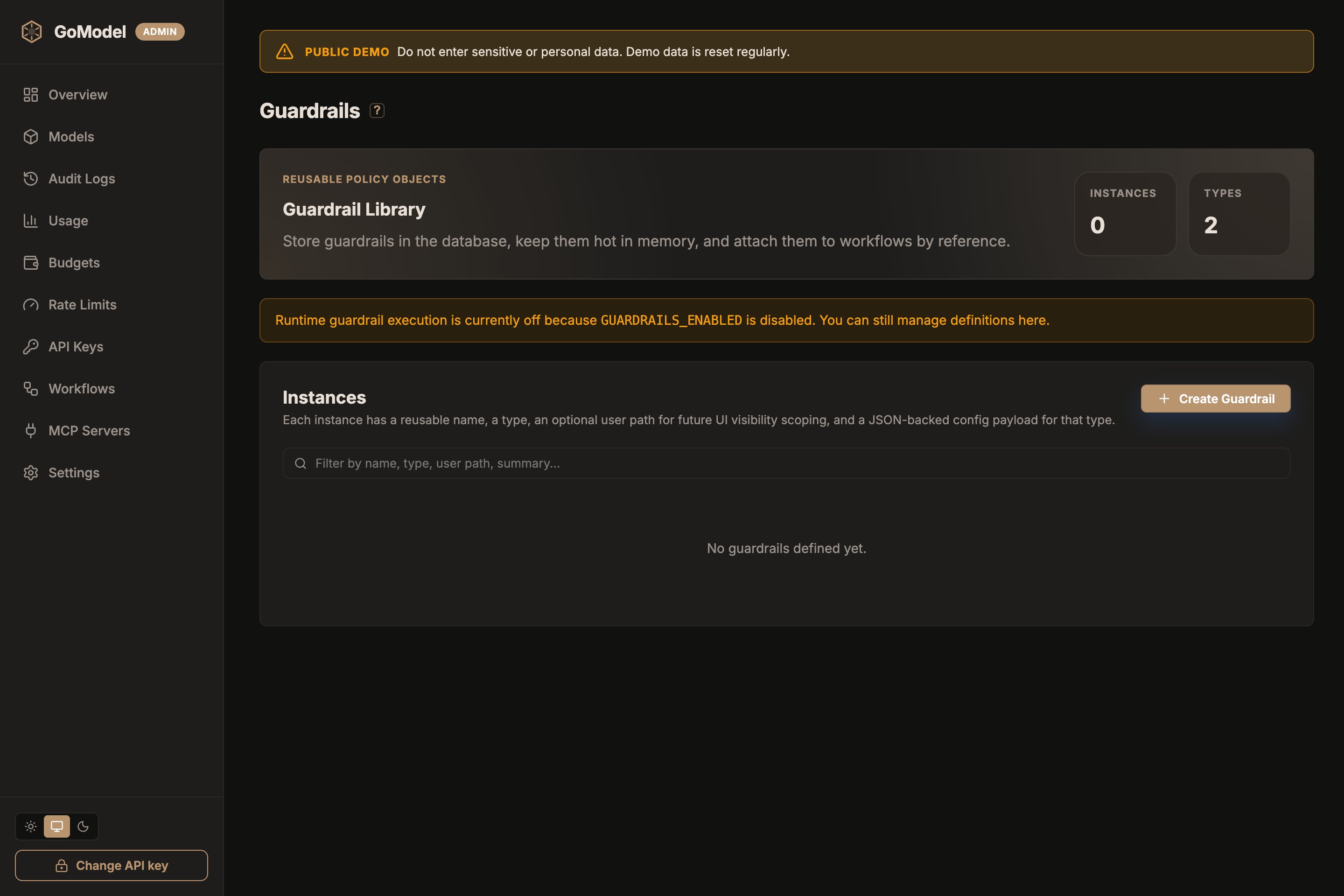
Manage from the Dashboard
Guardrail definitions can also be created and edited from the admin dashboard instead ofconfig.yaml — useful for iterating on rules without a
redeploy, or for operators who don’t manage this repo’s config directly.
system_prompt or
llm_based_altering), optionally scope it to a user_path, and fill in the
type-specific settings described below. config.yaml entries are seeded into
the same store at startup and stay in sync with it, so dashboard-created and
config-declared guardrails appear side by side.
Runtime guardrail execution still depends on
GUARDRAILS_ENABLED. With it
off, the page still lets you manage definitions — they just don’t run on
live traffic yet.How It Works
- Messages are extracted from the incoming request into a normalized format
- The guardrails pipeline processes the messages (inject, modify, or reject)
- Modified messages are applied back to the original request
- The request continues to the LLM provider
/chat/completions, /responses, and /messages.
Execution Order
Each guardrail has anorder value that controls when it runs:
- Same order → run in parallel (concurrently)
- Different order → run sequentially (ascending)
Configuration
Full Structure
Environment Variable
You can toggle guardrails without editing the config file:Rule Fields
Guardrail Types
system_prompt
Adds, replaces, or decorates the system prompt on every request.
Settings
Modes
- inject
- override
- decorator
Adds a system message only if none exists. Existing system prompts are left untouched.Behavior:
- Request has no system prompt → adds one
- Request already has a system prompt → no change
llm_based_altering
Rewrites selected message roles by calling an auxiliary model before the main
provider request runs. This is useful for PII anonymization and other
prompt-preserving rewrites.
The default prompt is derived from LiteLLM’s data_anonymization guardrail,
so a minimal config acts as an anonymizing preprocessor.
Settings
When
llm_based_altering calls the auxiliary model, GoModel runs that call
through the normal translated request path in-process. That means ordinary
workflow selection, failover, usage, audit, and cache behavior still apply.
The internal request uses:
- path:
/v1/chat/completions - user path:
{guardrail.user_path or caller user path}/guardrails/{guardrail name} - request origin:
guardrail